Valutare la qualità di uno studio: posso fidarmi di ciò che leggo?
Cerchiamo di capire come poter valutare in autonomia la validità di cosa si sta leggendo in letteratura scientifica.

Gli anni passano, la ricerca avanza e le nostre banche dati si arricchiscono sempre più. Purtroppo, tutto ciò porta con sé un numero maggiore di studi caratterizzati da scarso rigore metodologico ed elevato rischio di bias o errori sistematici (distorsioni che possono alterarne i risultati). È ormai noto come, nell’ambito della clinica e della formazione, si cerchi spesso e volentieri qualcuno che filtri le informazioni al posto nostro, qualcuno che le valuti e poi ce le ripresenti accompagnate da un voto o da qualche stellina. Ma come faccio a capire se posso fidarmi di ciò che leggo?
Quando prendiamo in considerazione studi che sono già stati valutati (pre-appraised) sarebbe bene porsi domande del tipo: “Che metodo è stato usato per definire la qualità di queste informazioni? È un metodo valido?” o ancora meglio “Posso riuscire a valutare anche da solo questi studi?”. Valutare in autonomia la validità di cosa si sta leggendo è possibile, ma presuppone una conoscenza e un corretto utilizzo dei vari step che compongono la “valutazione critica delle evidenze”.
Cos’è la valutazione critica delle evidenze?
Secondo l’organizzazione GIMBE:
“La valutazione critica della letteratura (critical appraisal) è un processo sequenziale che ha l’obiettivo di valutare metodologia, rilevanza ed applicabilità della ricerca pubblicata”. [1]
Quando si tratta di valutazione critica delle evidenze, le dimensioni che influenzano la qualità della ricerca sono 4:
- Validità interna
- Rilevanza
- Validità esterna (generalizzabilità e/o applicabilità)
- Consistenza (riproducibilità).
Il clinico che si approccia alla lettura di un articolo può porsi tre domande, le quali hanno il compito di individuare se lo studio che ha davanti rappresenti o meno la “migliore evidenza” per il proprio paziente. [2]
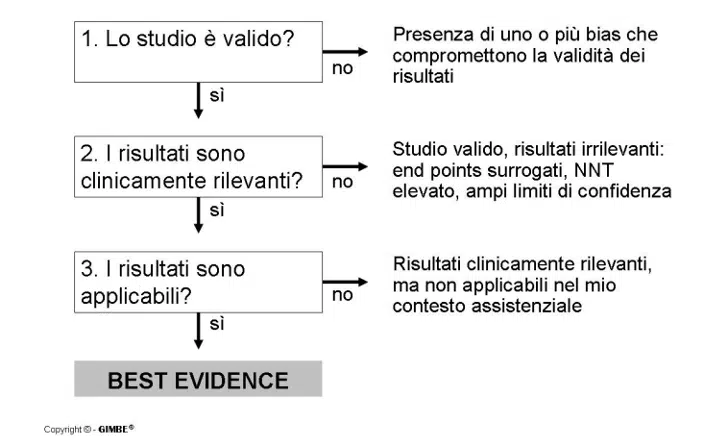
Come si può notare, nella parte destra del diagramma riportato, sono presenti le ragioni per cui si potrebbe dare una risposta negativa. Di seguito cercheremo di fornire tutti gli strumenti necessari per comprendere tali ragioni e permettere a chi si approccia alla valutazione critica di uno studio di sviluppare in autonomia il proprio giudizio.
Ma prima di partire cerchiamo di capire in che momento mi potrebbe essere utile valutare la qualità di uno studio.
Vi ricordate il signor Beppino? Ne avevamo parlato in un precedente articolo. Proprio oggi il signor Beppino ritorna nel vostro studio con un problema a voi del tutto sconosciuto, dopo aver fatto la vostra valutazione e averlo rassicurato sul fatto che non si tratti di nulla di grave, tornate a casa e decidete di approfondire un po’ la questione. Essendo dei “fisioterapisti basati sulle evidenze”, iniziate a cercare in lungo e in largo fra linee guida e revisioni sistematiche ma senza nessun risultato. Decidete così di dare un’occhiata ai trial clinici randomizzati (RCT) e… Bingo! Ecco qui un paio di RCT che parlano proprio della condizione del signor Beppino. Da una rapida lettura degli abstract troviamo chi dice che sia più efficace l’esercizio, chi la terapia manuale, chi la magia nera e chi consiglia di bere qualche bicchiere di vino rosso. Ma a chi bisogna credere? Di chi ci si può fidare? E soprattutto, chi sta cercando di vendere il suo vino come panacea per ogni male?
Nonostante sia molto improbabile trovare un RCT d’intervento sull’efficacia del vino rosso, è molto probabile trovarsi nella situazione di dover valutare degli studi con conclusioni differenti se non discordanti. Ed è proprio questo il momento in cui ci si rende conto che è necessario trovare le risposte alle nostre 3 domande se vogliamo aiutare al meglio il signor Beppino.
È doveroso premettere che gli strumenti e i concetti che verranno approfonditi sono principalmente inerenti alla valutazione critica di un trial clinico randomizzato (RCT) d’intervento. Si cercherà comunque di fornire indicazioni utili alla valutazione critica degli altri disegni di studio.
Lo studio è “valido”?
La validità o validità interna è strettamente correlata agli errori sistematici o bias, i quali potrebbero essere causa di compromissione dei risultati ottenuti. Le possibili tipologie di bias presenti si possono riscontrare durante tutte le fasi di produzione di uno studio. [2] Queste fasi prendono il nome di “ambiti” e sono descritte all’interno del “Revised Cochrane risk of bias tool for randomized trials (RoB 2)” [3], uno strumento utilizzato per la valutazione della validità interna dei trial clinici randomizzati e controllati (obiettivo comune alla PEdro Scale).[4]
Negli anni sono stati fatti diversi studi per valutare quale delle due scale sia la più adatta ad individuare uno studio metodologicamente valido. Tuttavia, non si hanno ancora risultati definitivi che garantiscono quale dei due strumenti sia più adatto. [5-8] Nonostante risulti uno strumento più complesso da applicare, si è scelto di analizzare più nel dettaglio il RoB 2 tool, il quale ci permette di ricavare maggiori informazioni e di valutare singolarmente ogni outcome ottenuto all’interno dello studio.
Come già anticipato, le tipologie di BIAS assumono il nome dalla fase dello studio in cui si possono riscontrare (fra parentesi il nome presente nella prima edizione del RoB). [9]
Le 5 tipologie di bias sono:
- Bias derivanti dal PROCESSO DI RANDOMIZZAZIONE (Selection bias)
- Bias derivanti da DEVIAZIONE RISPETTO ALL’INTERVENTO PROGRAMMATO (Performance bias)
- Bias derivanti dalla MANCANZA DI DATI (Attrition Bias)
- Bias nella MISURAZIONE DELL’ ESITO (Detection bias)
- Bias nel RIPORTARE I RISULTATI (Reporting bias)
La probabilità con cui, ognuno di questi bias, può essere presente all’interno di uno studio viene definita attraverso alcune domande (signalling questions) raccolte all’interno di diagrammi (flow charts) che proveremo ad analizzare più da vicino. Le possibili risposte ad ogni domanda saranno 5:
- YES (Y)
- PROBABLY YES (PY)
- NO INFORMATION (NI)
- PROBABLY NO (PN)
- NO (N)
Utilizzando queste risposte sarà possibile ottenere per ogni bias un giudizio riguardo la probabilità che esso sia presente o meno:
- Basso Rischio
- Alcune preoccupazioni
- Alto rischio [9]
Naturalmente più alto sarà il rischio e meno ci sarà da fidarci di ciò che leggiamo.
È arrivato il momento di proseguire la nostra valutazione critica di uno studio, partendo dalla prima tipologia di bias riscontrabile in un RCT. Per ogni rischio di bias verrà riportata la flow chart con le relative signalling questions (in blu). Si proverà a sviscerare i concetti più importanti e affiancarle dalla sezione dell’articolo in cui si potrebbe (ma non necessariamente) trovare la risposta.
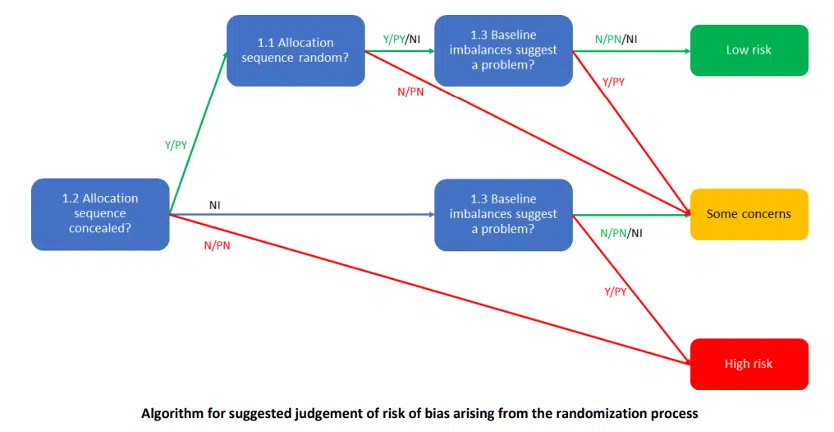
Bias derivanti dal processo di randomizzazione
Partiamo dai concetti necessari per comprendere la prima flow chart: il processo di assegnazione casuale e le differenze al baseline.
- Il processo di assegnazione casuale consiste in 2 fasi [10]:
- Generare una sequenza random imprevedibile. La randomizzazione viene spesso definita come “l’assegnazione casuale dei pazienti al gruppo sperimentale o di controllo, al fine di assicurare che tutti i fattori prognostici – noti e sconosciuti – si distribuiscano omogeneamente nei due gruppi” [10.
- Implementare la sequenza facendo in modo di nascondere i trattamenti fino a quando i pazienti non sono stati assegnati ai loro gruppi. Sia questa informazione, necessaria per rispondere alla domanda 1.2 che il processo di randomizazzione (1.1) possono essere ritrovate all’interno della sezione: “Materiali e metodi”.
- Le differenze al baseline. (1.3) Solitamente, osservando la Tabella 1 degli RCT, si ritrova la “distribuzione dei dati demografici fra i gruppi”. All’interno della tabella sarà presente una colonna “p” in cui sarà associato un p-value per ogni variabile riportata. Nel caso avessimo sempre p>0,05 (ASSENZA di differenza statisticamente significativa) allora la randomizzazione risulta valida con i due o più gruppi omogenei fra di loro. [11]
Bias derivanti da deviazione rispetto all’intervento programmato
Partiamo dai concetti necessari per comprendere la prima flow chart: il processo di assegnazione casuale e le differenze al baseline.
Il processo di assegnazione casuale consiste in 2 fasi [10]:
- Generare una sequenza random imprevedibile. La randomizzazione viene spesso definita come “l’assegnazione casuale dei pazienti al gruppo sperimentale o di controllo, al fine di assicurare che tutti i fattori prognostici – noti e sconosciuti – si distribuiscano omogeneamente nei due gruppi” [10].
- Implementare la sequenza facendo in modo di nascondere i trattamenti fino a quando i pazienti non sono stati assegnati ai loro gruppi. Sia questa informazione, necessaria per rispondere alla domanda 1.2 che il processo di randomizazzione (1.1) possono essere ritrovate all’interno della sezione: “Materiali e metodi”.
Le differenze al baseline. (1.3) Solitamente, osservando la Tabella 1 degli RCT, si ritrova la “distribuzione dei dati demografici fra i gruppi”. All’interno della tabella sarà presente una colonna “p” in cui sarà associato un p-value per ogni variabile riportata. Nel caso avessimo sempre p>0,05 (ASSENZA di differenza statisticamente significativa) allora la randomizzazione risulta valida con i due o più gruppi omogenei fra di loro. [11]
Bias derivanti da deviazione rispetto all’intervento programmato
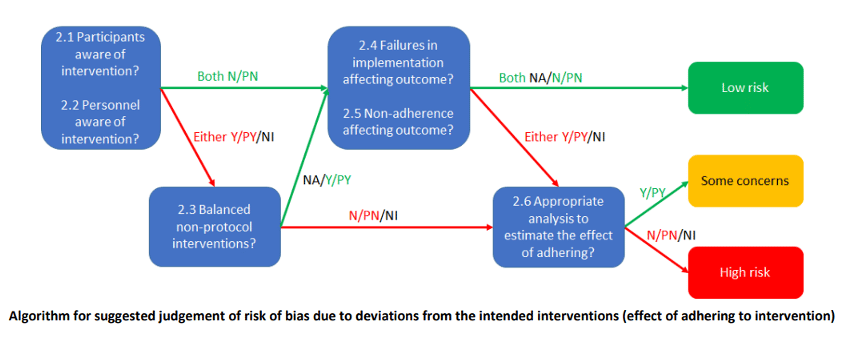
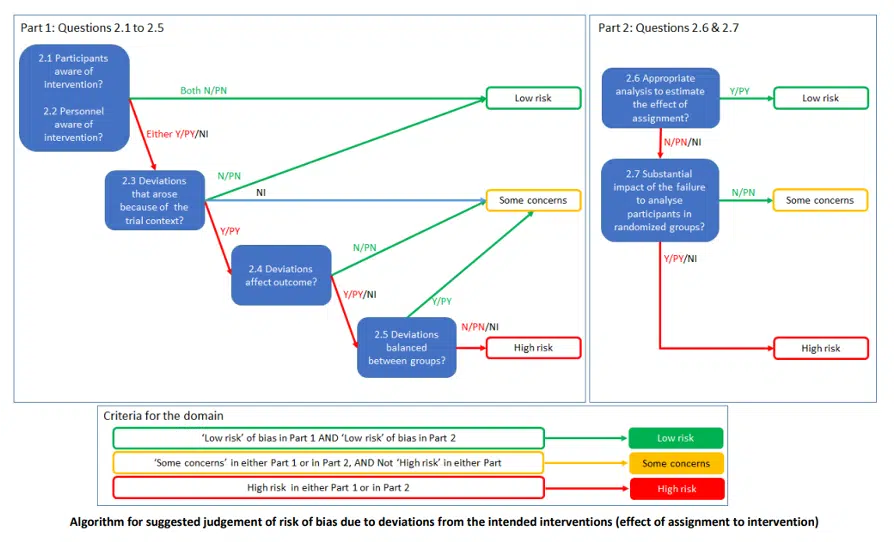
Come si è potuto notare per questa tipologia di bias sono presenti due flow chart. La prima (effect of assignement to intervention) viene utilizzata nei casi in cui ci siano stati dei problemi di assegnazione dei pazienti dopo il baseline (es. un paziente che non riceve il trattamento del gruppo in cui era stato inserito) mentre la seconda, (effect of adhering to intervention), viene utilizzata nel caso in cui si siano verificati problemi dovuti all’aderenza al trattamento (es. erano previste nel protocollo 3 settimane di trattamento e il clinico ne somministra solo 2). Naturalmente la scelta della flow chart dipende dal contesto dello studio e sarà compito nostro stabilirlo.
I concetti necessari per la comprensione di queste flow chart sono:
- La cecità (2.1 – 2.2). Come ben sappiamo: “la cecità impedisce a una o più categorie di soggetti coinvolti nel trial di conoscere il trattamento assegnato “[12] La cecità di entrambi gli attori, personale e partecipanti, condurrebbe ad un basso rischio di bias. Purtroppo, però si tratta di situazioni piuttosto rare nell’ambito fisioterapico vista la difficoltà nel nascondere al professionista il trattamento che egli stesso sta somministrando.
- Il protocollo di studio. (2.3 – 2.4 – 2.5 prima flow chart) All’interno del “Guideline for good clinical practice” viene indicato come: “Il documento che descrive l’obiettivo, la progettazione, la metodologia, le considerazioni statistiche e l’organizzazione di uno studio. Il protocollo solitamente fornisce anche le informazioni di base e il razionale di uno studio clinico […] “.[13] L’intervento programmato è descritto all’interno del protocollo, il quale è reperibile utilizzando il codice NCT (presente nell’abstract) sul sito Clinicaltrials.gov [14]. Nel caso in cui non sia reperibile, all’interno della sezione “Materiali e metodi” possiamo trovare informazioni riguardo l’intervento programmato. È necessario notare se sono state eseguite modifiche senza essere esplicitate e motivate e se queste modifiche possano avere o meno influito sui risultati.
- Il metodo di analisi per la stima dell’effetto (2.6). A causa della possibile perdita di dati o non aderenza al trattamento da parte dei pazienti, la stima dell’effetto ottenuta potrebbe essere sovra o sottostimata. Per ovviare a tale problema negli RCT viene consigliato l’utilizzo dell’Intention to treat analysis (ITT) odell’ITT modificata. Trattandosi di un concetto d’inerenza statistica ci limiteremo a riportare che: “L’analisi ITT comprende tutti i soggetti randomizzati in base all’assegnazione del trattamento. Ignora la non conformità, le deviazioni dal protocollo, i ritiri e tutto ciò che accade dopo la randomizzazione. L’analisi ITT mantiene l’equilibrio prognostico generato dall’assegnazione casuale del trattamento originale.” [15]
In caso fosse necessario approfondire qualsiasi informazione inerente all’utilizzo del RoB 2 tool si ricorda la presenza del Revised Cochrane risk-of-bias tool for randomized trials SHORT VERSION (CRIBSHEET).[16]
Bias derivanti dalla mancanza di dati
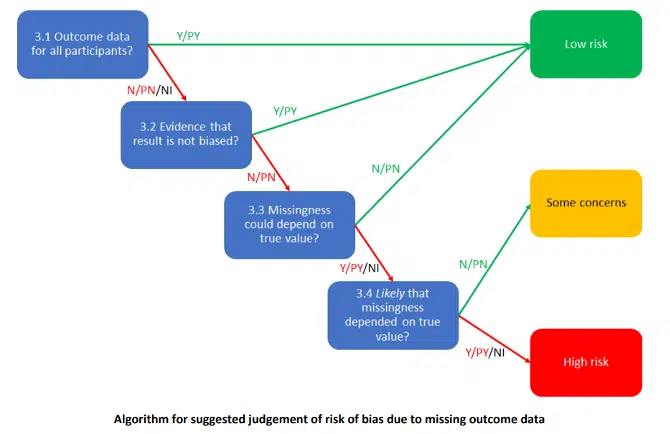
Per valutare la presenza del rischio di bias derivanti dalla mancanza di dati si tengono in considerazione:
- La percentuale di dati disponibili sul totale programmato (3.1). Come riportato all’interno del CRIBSHEET: “Per gli outcome continui, la disponibilità dei dati del 95% dei partecipanti sarà spesso sufficiente. Per outcome dicotomici, la proporzione richiesta è direttamente collegata al rischio dell’evento.” [16] (vedi sezione “Risultati” e relative tabelle)
- Le evidenze che il risultato non sia stato falsato (3.2). Sempre all’interno del CRIBSHEET possiamo ritrovare che: “L’evidenza che il risultato non sia stato falsato dalla mancanza di dati sugli esiti può derivare da: metodi di analisi per la correzione dei bias e analisi di sensibilità che mostrano una piccola variazione se si ipotizza una relazione fra la mancanza di dati sull’outcome e il suo valore reale.” [16] (vedi “Risultati” o “Analisi dei dati”)
- La correlazione fra i dati mancanti e il true value (3.3 – 3.4). Ciò che dovremmo chiederci è se la perdita al follow up sia stata causata dall’intervento o da ragioni proprie del soggetto non dipendenti dall’intervento. Provando a fare un esempio: il primo giorno la terapia induce problemi di salute al paziente che il giorno seguente non si presenta e riferisce dei problemi di salute. Il “true value” o “vero valore” che avrei dovuto osservare è “la terapia ha causato un problema di salute” ma non l’ho potuto fare perché il paziente non si è presentato. In questo caso la correlazione fra i dati mancanti e il vero valore esiste e aumenta il rischio di bias dello studio, soprattutto se il numero di pazienti in questa situazione è elevato. Per questa ragione ogni perdita al follow up deve essere documentata e motivata dagli autori.
Bias nella misurazione dell’esito
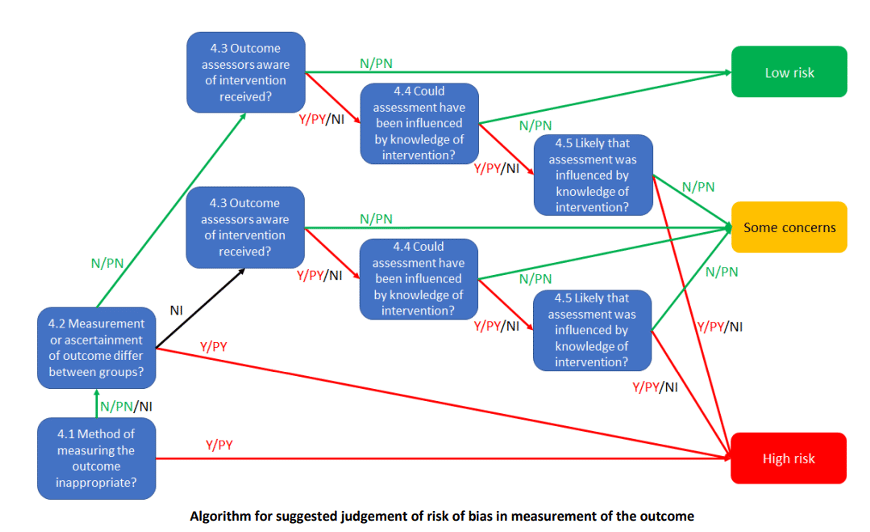
Nonostante la complessità di questa flow chart i concetti fondamenti per valutare la presenza del rischio di bias nella misurazione dell’esito all’interno dello studio sono principalmente due:
- Modalità di misurazione dell’outcome. È fondamentale individuare se lo strumento utilizzato per valutare gli outcome (vedi sezione “Materiali e Metodi”) è appropriato (4.1) e se le misurazioni differiscono tra i due gruppi (4.2). All’interno del CRIBSHEET una modalità di misurazione dell’outcome viene considerata inappropriata perché: “è improbabile che sia sensibile agli effetti plausibili dell’intervento oppure è stato dimostrato che lo strumento di misura ha scarsa validità”. [16] Pensiamo per esempio di applicare un programma riabilitativo di 12 settimane di terapia manuale ed esercizio con lo scopo di ridurre il dolore e la disabilità percepiti. Strumenti adatti per la valutazione dell’outcome dolore potrebbero essere una scala VAS oppure questionari sulla disabilità percepita, ma non l’utilizzo di indagini diagnostiche.
La cecità di coloro che valutano l’outcome (outcome assessors). Come riportato all’interno del CRIBSHEET, alla domanda 4.3: “Rispondere “No” se i valutatori dell’esito erano in cieco rispetto allo stato dell’intervento. Per gli esiti riferiti dai partecipanti il valutatore dell’esito è il partecipante allo studio.” [16]Dopo aver confermato che l’outcome assessors sia o meno a conoscenza dell’intervento assegnato non ci resta che individuare se la valuazione dell’outcome potrebbe essere stata influenzata(4.4) e, se sì, con che probabilità(4.5). Tutte informazioni che possiamo ricavare individualmente, utilizzando il nostro ragionamento e un po’ di buon senso.
Bias nel riportare i risultati
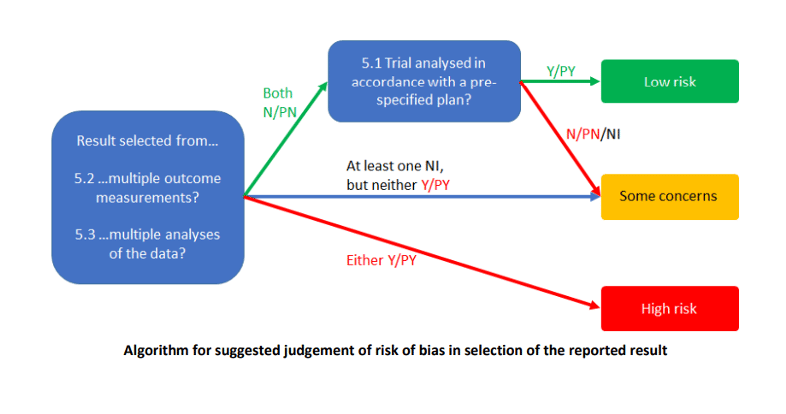
Per utilizzare l’ultima flow chart il concetto da approfondire è quello del selective reporting.
- Selective reporting. Per rispondere alle domande 5.2 e 5.3 è necessario individuare se gli autori, all’interno del protocollo o dello studio, abbiano eseguito più misurazioni dello stesso outcome (outcome dolore misurato sia con VAS che con questionari inerenti) e più analisi statistiche differenti e abbiano poi deciso di riportare solo una parte di queste misurazioni e analisi nella sezione “Risultati”. Come viene spiegato all’interno del CRIBSHEET: “La selezione dei risultati può derivare dal desiderio che le scoperte facciano notizia, che siano sufficientemente degni di nota da meritare la pubblicazione o che confermino un’ipotesi precedente.” [16]
Arrivati al termine appare abbastanza chiaro che il processo di valutazione della validità interna di uno studio risulta essere macchinoso e complesso se applicato alla lettera.È doveroso ricordare che questo strumento viene utilizzato in maniera rigorosa da chi si occupa di valutare il rischio di bias negli RCT per la successiva stesura delle revisioni sistematiche. Il buon senso impone che, avere un’idea di quelle che sono le fasi di un RCT in cui si possa riscontrare un determinato bias possa aiutare il clinico nel formulare un primo giudizio del rischio di bias.
Proseguendo attraverso gli step della valutazione critica delle evidenze abbiamo individuato gli studi che ci risultano essere a “basso rischio di bias” e non vediamo l’ora di poter modificare il trattamento del giorno seguente. Nel frattempo, il nostro signor Beppino è seduto a tavola, a struggersi dal male mentre segue il suo TG serale e sorseggia il suo bicchiere di vino rosso sperando che la seduta del giorno dopo lo aiuti a stare meglio. Ma noi siamo davvero sicuri che ciò che abbiamo letto possa esserci d’aiuto solo perché è considerato “a basso rischio di bias?” E se si trattasse di risultati non rilevanti per il nostro signor Beppino?
I risultati sono clinicamente rilevanti?
Come scrive Antonino Cartabellotta riguardo al concetto di rilevanza clinica: “Nel critical appraisal corrisponde alla fase di analisi dei risultati e misura – oltre la significatività statistica – l’entità ela precisione dei benefici del trattamento.” [2]
Prima di parlare di rilevanza clinica è necessario aprire una breve parentesi sulla “rilevanza statistica” e in particolare sul concetto di significatività statistica. Per esporre al meglio tale concetto sarebbe opportuno approfondire aspetti come: l’ipotesi nulla, gli intervalli di confidenza, i test di ipotesi etc. Considerando però che lo scopo di questo articolo è quello di fornire informazioni necessarie a valutare la qualità delle evidenze scientifiche ci limiteremo a riassumere il concetto di significatività statistica in due punti:
- Si tratta di una probabilità rappresentata come “p” o “p-value” (valore compreso fra 0 e 1) ed affianca ogni risultato ottenuto da un test statistico.
- Come si legge all’interno del libro Evidence Based Practice: “[…] il p-value rappresenta la probabilità che il risultato trovato sia dovuto al caso, invece che al fenomeno in esame”. [17] Ciò che interessa a noi fruitori delle evidenze è notare se tale valore sia inferiore a 0,05 (meno del 5% di probabilità che ciò che si è osservato sia dovuto al caso). Il valore 5% come limite viene solitamente settato dagli autori, in alcuni casi (soprattutto in ambito farmacologico) viene scelto un livello di significatività inferiore, ovvero dell’1%. [18]
Quindi, a cosa dovremmo porre l’attenzione durante la valutazione critica di uno studio per individuare se esso è clinicamente rilevante o meno? È Sempre Cartabellotta [2] a ricordarci che i fattori che influenzano la rilevanza clinica nei trial sono:
- End-point misurato. Possiamo trovarci di fronte ad un outcome clinicamente rilevante oppure surrogato. Che cosa li distingue? Secondo Cartabellotta gli outcome clinicamente rilevanti: “Comprendono, oltre la mortalità, tutti gli eventi clinici morbosi che possono essere rilevati nel corso della storia naturale/post-terapeutica di una malattia.” [20]. Ed è sempre lui a ricordarci che gli outcome surrogati” […] sono variabili anatomico-fisiologico-metaboliche misurate con test di laboratorio / strumentali. Vengono utilizzati con la presunzione di dimostrare l’efficacia del trattamento su un end-point clinicamente rilevante senza misurarlo direttamente”. [20] All’interno della sezione “Materiali e metodi” troverò gli outcome classificati come primari e secondari, ma com’è facile intuire nessuno dichiarerà se l’outcome è surrogato o clinicamente rilevante. A questo punto sarà fondamentale per il clinico avere una conoscenza di cosa è effettivamente rilevante per la patologia presa in esame: le alterazioni strumentali? il ROM? oppure la disabilità percepita?…
- Number needed to Treat (NNT). Numero di pazienti da trattare per ottenere un beneficio. Maggiore sarà il NNT e minore sarà l’efficacia del trattamento applicato.
- Number needed to Harm (NNH). Numero di pazienti da trattare per osservare un effetto avverso. Maggiore sarà il NNH e maggiore sarà la sicurezza del trattamento applicato.
- Precisione dei risultati. Quest’ultima è relativa all’ampiezza degli intervalli di confidenza. Se l’ampiezza degli intervalli di confidenza di una stima è elevata e comprende al suo interno il valore 0 (assenza di differenza fra i due gruppi) o addirittura un valore negativo (maggiore efficacia del gruppo di controllo) dovrò tenere in considerazione che l’intervento potrebbe essere più efficace del controllo ma anche avere la stessa se non minore efficacia, contribuendo così in maniera importante a giudicare se tale outcome sarà clinicamente rilevante o meno.
Com’è possibile individuare all’interno del libro “Evidence Based Practice” [17] altre variabili fondamentali che potrebbero definire la rilevanza clinica di un RCT di intervento sono:
- Effect size o dimensione dell’effetto. Definita come: “l’ampiezza della differenza fra i due gruppi” [19] A parità di tutti gli altri fattori presi in considerazione, maggiore sarà la dimensione dell’effetto di un RCT e più rilevante sarà per il mio paziente.
- Minimal Clinically Important DIfference (MCID). Definita come: “quantità di cambiamento considerabile clinicamente significativa per il paziente” [17]
- Popolazione, sample size e timing.
Se ci trovassimo di fronte a studi differenti da quelli d’intervento la valutazione della rilevanza clinica dovrà tenere conto di fattori differenti fra i quali:
- Likehood Ratio per gli studi di accuratezza diagnostica.
- Odds Ratio (OR) e relative risk (RR) per gli studi di tipo prognostico.
- Nel caso di studi secondari, oltre ad essere considerato valido tutto ciò che si è detto riguardo gli studi primari, può essere utilizzato uno strumento convalidato per valutare la forza delle raccomandazioni e la qualità delle evidenze: il GRADE (Grading of Recommendations Assessment, Develepment and Evaluation.[20]
I risultati sono applicabili?
Siamo giunti al termine del nostro percorso di valutazione critica delle evidenze, è il momento di capire se ciò che ho letto, considerato valido e clinicamente rilevante, può finalmente essere applicato al caro signor Beppino! Ma come capisco se i risultati dello studio sono applicabili o meno?
Cartabelotta definisce il concetto di applicabilità come: “il grado con cui i risultati dello studio possono essere applicati al proprio contesto assistenziale e, nello specifico al paziente individuale”. [2]
I fattori considerati che influiscono, indipendentemente dal disegno di studio, sull’applicabilità o meno delle evidenze sono vari [2]:
- I criteri di inclusione/esclusione che definiscono i pazienti arruolati nello studio.
- Il setting in cui viene condotto lo studio. Un fattore vasto che comprende al suo interno strumenti e strutture disponibili durante lo studio ma anche le competenze del fisioterapista che applica il trattamento. In effetti, lo stesso trattamento applicato alla stessa tipologia di pazienti in spazi differenti e da professionisti con differenti livelli di competenza potrebbe riportare risultati diversi.
- La descrizione accurata e completa di quelle che sono le procedure e le modalità di erogazione del trattamento.
Ci sarebbe molto altro da dire al riguardo, purtroppo però gli spazi di un articolo di blog non lo permettono, in caso fosse necessario approfondire si rimanda al libro “Evidence Based Practice”. Detto ciò, si è scelto di dedicare un breve paragrafo al concetto di “consistenza” che abbiamo solo citato in precedenza.
I risultati sono consistenti?
Esiste a tutti gli effetti una quarta domanda che si rifà al concetto di consistenza, la quale: “Documenta che i risultati di uno studio vengono confermati da studi simili; per tale ragione la consistenza è una caratteristica esclusiva delle revisioni sistematiche con meta-analisi che permette di apprezzare graficamente se i risultati dei vari studi sono simili o discordanti” [2]
È quindi chiaro che nei singoli RCT emersi dalla nostra ricerca non è possibile individuare la presenza di consistenza fra i risultati, tuttavia, avendo una conoscenza della letteratura recente, si possono individuare i risultati concordi o discordi rispetto alle attuali evidenze scientifiche.
In conclusione, dopo aver accennato alla “consistenza” è doveroso tenere presente anche il concetto di “integrità”. Come si può leggere all’interno del manifesto “L’integrità nella ricerca” del Policlinico di Torino: “Per integrità nella ricerca si intende l’adesione all’insieme dei principi e dei valori etici, dei doveri deontologici e degli standard professionali necessari per una condotta responsabile e corretta nello svolgimento della ricerca scientifica e in tutte le attività ad essa connesse” [21].
Tra questi, all’interno della sezione “Conflitti di interessi”, vengono solitamente riportati i fattori che avrebbero potuto influenzare la condotta dei ricercatori durante l’esecuzione e la stesura dello studio. Nel caso in cui, nonostante non vengano dichiarati conflitti di interesse, si abbiano comunque dubbi al riguardo, sarà più semplice capire quanta fiducia dare agli autori. Infatti, siamo adesso capaci di individuare tutto ciò che andrebbe riportato all’interno di uno studio e le modalità con cui dovrebbe essere fatto.
Conclusione
Alla fine del nostro percorso è opportuno ribadire come, ancora una volta, il ragionamento supportato dalle giuste conoscenze diventi l’arma migliore che un fisioterapista possa avere. Appare evidente quanti siano i limiti e gli ostacoli: il tempo, la difficoltà di utilizzo degli strumenti e la lontananza fra mondo clinico e ricerca. Come esistono i limiti però, esistono anche i mezzi per superarli ed una raccolta di tali mezzi è presente all’interno della rubrica “#PedroTackesBarrier.” [22] Svariati sono i consigli di ricercatori e clinici riguardo il districarsi fra le banche dati e la valutazione delle evidenze. Fra questi emerge la ricerca di colleghi con interessi comuni e pronti a dividersi il lavoro intesa come possibilità di risparmiare tempo, avere differenti punti di vista e permetterci di acquisire maggiore libertà.
Infatti, avere le capacità di valutare in autonomia ciò che leggiamo, ci rende liberi di poter mettere in discussione ciò che ci viene spesso venduto come “chiaro e valido” anche quando le cose sono tutt’altro che chiare. Avere la possibilità di dire la nostra, supportati dalle giuste conoscenze, favorisce, giorno dopo giorno, quel confronto necessario sia alla crescita personale che professionale. Sperando di trovarvi concordi, come scrive Ashihs Dev Gari: “I just want to leave the profession better than i found it”.
-
- Handbook “Competenze core per l’Evidence-based Practice”. Disponibile a: gimbe.org/EBP.
- Cartabellotta, A. (2009). L’approccio critico alla letteratura biomedica. Quali dimensioni influenzano la qualità della ricerca clinica? GIMBEnews 2009; 5:2-3.
- Sterne, J., Savović, J., Page, M. J., Elbers, R. G., Blencowe, N. S., Boutron, I., Cates, C. J., Cheng, H. Y., Corbett, M. S., Eldridge, S. M., Emberson, J. R., Hernán, M. A., Hopewell, S., Hróbjartsson, A., Junqueira, D. R., Jüni, P., Kirkham, J. J., Lasserson, T., Li, T., McAleenan, A., … Higgins, J. (2019). RoB 2: a revised tool for assessing risk of bias in randomised trials. BMJ (Clinical research ed.), 366, l4898.
- Herbert, R., Sherrington, C., Moseley, A., Maher, C., Elkins, M., & Kamper, S. PEDro Scale. Disponibile a: https://pedro.org.au/italian/resources/pedro-scale/
- Moseley, A. M., Rahman, P., Wells, G. A., Zadro, J. R., Sherrington, C., Toupin-April, K., & Brosseau, L. (2019). Agreement between the Cochrane risk of bias tool and Physiotherapy Evidence Database (PEDro) scale: A meta-epidemiological study of randomized controlled trials of physical therapy interventions. PloS one, 14(9), e0222770.
- Armijo-Olivo, S., da Costa, B. R., Cummings, G. G., Ha, C., Fuentes, J., Saltaji, H., & Egger, M. (2015). PEDro or Cochrane to Assess the Quality of Clinical Trials? A Meta-Epidemiological Study. PloS one, 10(7), e0132634.
- Minozzi, S., Cinquini, M., Gianola, S., Gonzalez-Lorenzo, M., & Banzi, R. (2020). The revised Cochrane risk of bias tool for randomized trials (RoB 2) showed low interrater reliability and challenges in its application. Journal of clinical epidemiology, 126, 37–44.
- Albanese, E., Bütikofer, L., Armijo-Olivo, S., Ha, C., & Egger, M. (2020). Construct validity of the Physiotherapy Evidence Database (PEDro) quality scale for randomized trials: Item response theory and factor analyses. Research synthesis methods, 11(2), 227–236.
- Higgins, J.P.T., Thomas, J., Chandler, J., Cumpston, M., Li, T., Page, M.J., Welch, V.A., (editors). Cochrane Handbook for Systematic Reviews of Interventions version 6.3 (updated February 2022). Cochrane, 2022. Available from training.cochrane.org/handbook.
- Cartabellotta, A., (2009). Randomizzazione: quando decide il caso. Gli strumenti per prevenire il bias di selezione nei trial clinici GIMBEnews 2009; 1:2-3
- Nahm, Francis Sahngun. “What the P values really tell us.” The Korean journal of pain 30,4 (2017): 241-242. doi: 10.3344/kjp.2017.30.4.241
- Cartabellotta, A., (2009). Blinding: chi ha gli occhi coperti? L’ambiguità terminologica di singolo, doppio e triplo cieco. GIMBEnews 2009; 2:2-3
- Good Clinical Practice (GCP) E6(R2). Disponibile a: ich.org/page/efficacy-guidelines
- ClinicalTrials: database di studi clinici finanziati privatamente e pubblicamente condotti in tutto il mondo. Disponibile a: https://clinicaltrials.gov/.
- Gupta, Sandeep, K., (2011). “Intention-to-treat concept: A review.” Perspectives in clinical research 2,3: 109-12. doi: 10.4103/2229-3485.83221
- Revised Cochrane risk-of-bias tool for randomized trials (RoB 2) Short Version (CRIBSHEET) Disponibile a: https://www.riskofbias.info/welcome/rob-2-0-tool/current-version-of-rob-2
- Barbari, V., Ramponi, N. (2021). Evidence Based Practice. La guida completa per il professionista della salute. Capitolo 9: 307-427
- Flechner, L., & Tseng, T. Y. (2011). Understanding results: P-values, confidence intervals, and number need to treat. Indian journal of urology : IJU: journal of the Urological Society of India, 27(4), 532–535.
- Sullivan, G. M., & Feinn, R. (2012). Using Effect Size-or Why the P Value Is Not Enough. Journal of graduate medical education, 4(3), 279–282. https://doi.org/10.4300/JGME-D-12-00156.1
- Guyatt, G. H., Oxman, A. D., Vist, G. E., Kunz, R., Falck-Ytter, Y., Alonso-Coello, P., Schünemann, H. J., & GRADE Working Group (2008). GRADE: an emerging consensus on rating quality of evidence and strength of recommendations. BMJ (Clinical research ed.), 336(7650), 924–926. https://doi.org/10.1136/bmj.39489.470347.AD
- Manifesto integrità nella ricerca: Policlinico di Torino. Disponibile a: https://www.polito.it/ricerca/integrita/
- Physiotherapy Evidence Database. #PEDroTacklesBarriers to EBP. Disponibile a: https://pedro.org.au/italian/learn/pedrotacklesbarriers-to-ebp/